上一篇说了pytorch下利用其Dataset和DataLoaderapi可以很方便地实现动态读取数据,不需要将图片保存到本地也可以快速取样本.
在TensorFlow下之前写过常用的数据读取方式,在TF1.3版本新添加了Dataset模块,1.3版本中其位于
tf.contrib.data.Dataset,1.4版本后移到了’tf.data.Dataset’.
之前的tfrecord队列读取数据的方式有一些不足:
- 需要保存为tfrecord文件格式,官方doc有些晦涩难懂=,学习成本较高(相比于pytorch dataset的实现)
- 需要保存为tfrecord文件,占用一定硬盘空间
- 其内部机制有些难懂,最后如果结果不对,不能保证是不是样本读取代码这里出了问题
构建一个Dataset
首先,Dataset结构:
从这里也可以看到,跟pytorch下的很像,一个好处就是相比之前的队列或者feed_dict来说要简单,简介许多,代码易读性也增加了.
- Dataset模块: 包含基本的方法,如创建dataset, 随机(shuffle), 变换(transformation), 批处理(batch)等
- 子类: 针对特定数据的一些方便的子类,就像pytorch中的labeledImageDataset等
- Dataset的方法就是实例化一个Iterator对象,保证每次取到一个dataset中的一个/批样本.
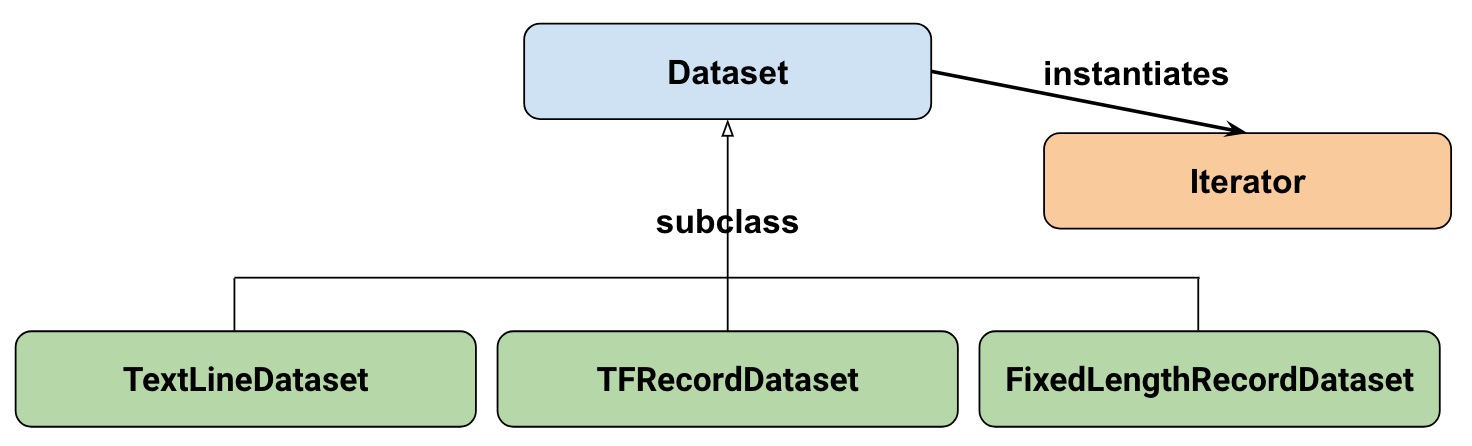
从官方doc我们可以看到,构建一个Dataset的大致的几个方法有:
from_generator:调用了py_func方法,可以将任意的python代码转化为tf图中的operation节点;使用指定生成器中的每个元素作为dataset中的元素from_sparse_tensor_slicesfrom_tensor_slices
example
利用from_generator方法来实现之前的动态生成训练和测试样本.
从一些3D图片中随机取一些[128, 128, 128]大小的样本, 原图和金标准图index要一致,每个样本包含(data, target), 为了方便,提前保存好了这些样本的行列坐标.
1 | import tensorflow as tf |
之后可以从时间较多对比下~,其实之前做过一些测试,发现tfrecord和pytorch下Dataset&DataLoader时间相差无几.