最近使用TensorFlow时候发现读入图片数据的时候很难受,自己写的一些代码又感觉很蹩脚,官方的文档易读性太低,太费劲了.
打算好好整理一下数据输入这部分代码.
方式
直接加载到内存中
这种方式简直暴力,老早之前我数据没有很多,就是这么做的,把数据先用pickle,将其保存下来,运行的时候直接从保存的文件中获取,这种方式只适合一些小型的文本文件数据,图片数据还是算了,电脑会卡死的.
动态输入placeholder
在每次训练时加载一些数据到内存当中,以placeholder的形式feed到graph当中.
这种方式需要自己写一些代码,比如
1 | class ImageData: |
在训练时实例化相应的类, 每次运行加载一次,需要说明的是,这样需要大量地重复读写多个小文件,所以把这些文件放到固态硬盘下面对提升读取速度是个不错的选择.
这个方法是比较类似于pytorch的dataset和dataloader的,同时采用pytorch的这两个类来实现TF中的数据输入也是很可行的.
详情见Data Loading and Processing Tutorial.
tfrecord
TF推荐的一种文件格式为tfrecord,把多个零碎的原始文件编码为一个较大的tfrecord文件,运行时通过解码器将其转化为Tensors, 这篇tutorial解释了TF中读入数据的方法,这里代码已经写得很好了,但读完发现还是不会……
可能用到的TF对象和方法, (先大致看名字了解一下,详细后面会涉及到):
tf.TFRecordReadertf.train.string_input_producertf.decode_raw()tf.train.shuffle_batch()tf.parse_single_exampletf.train.Coordinator()tf.train.start_queue_runners
数据转化
首先通过一个tf.TFRecordWriter对象将原始零碎小文件转化为tfrecord格式文件,代码参考某个地方的:
1 | writer = tf.python_io.TFRecordWriter('./data/test_deepmatching.tfrecords') # 初始化TFRecordWriter对象 |
读入tfrecord
TF将文件名生成队列,并行解码读取里面的Tensors.
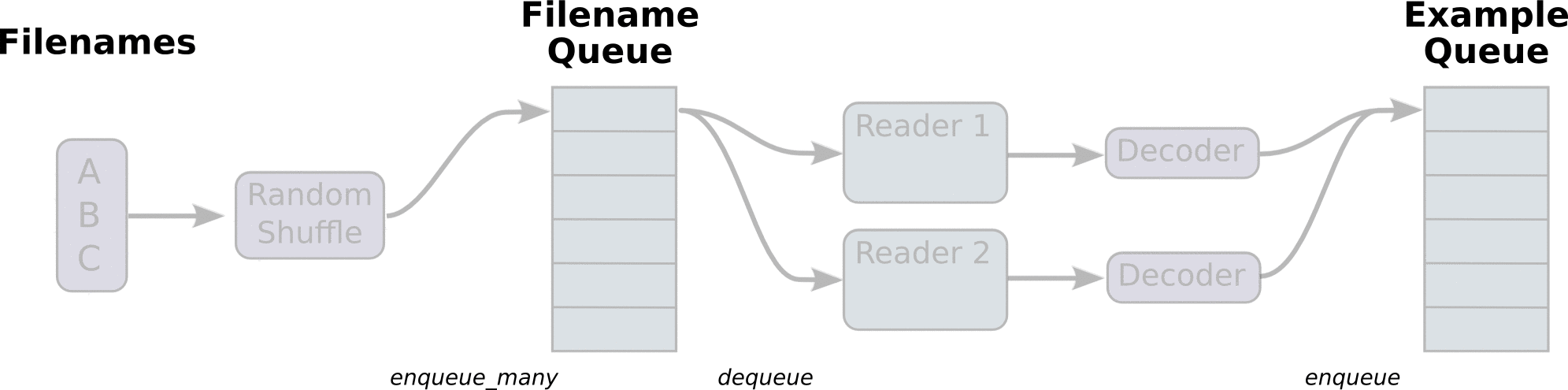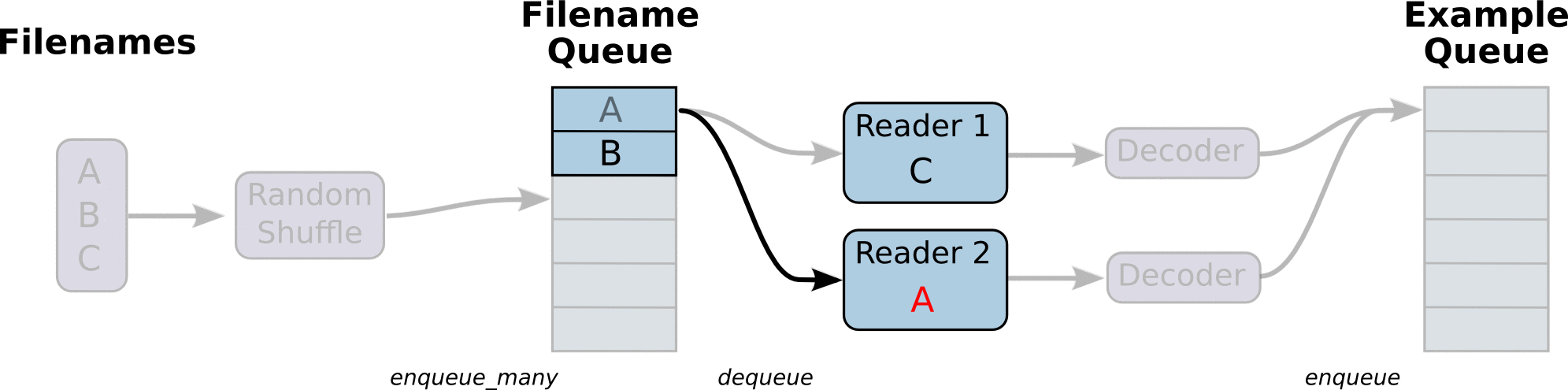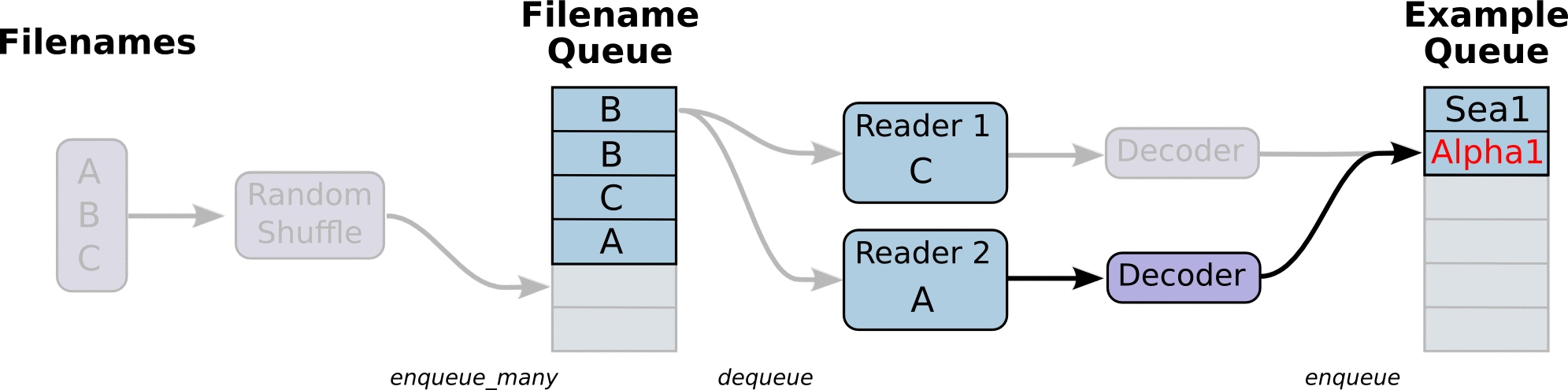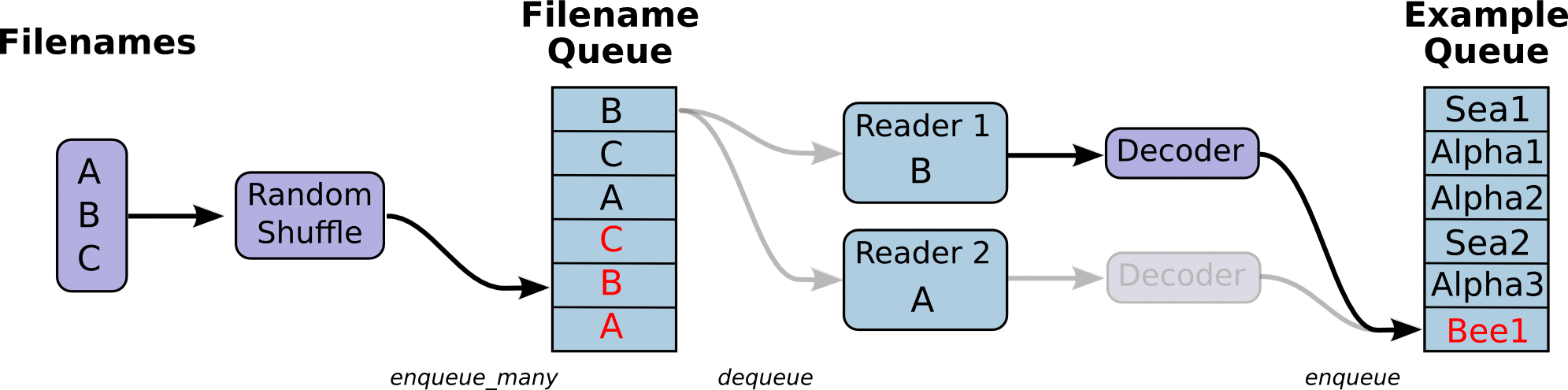
1 | def read_and_decode(filename): |
上述函数返回我们的img 和label ops,运行时候还需要run一下这几个ops.
为了实现并行读取,我们需要创建多个线程,使用QueueRunner兑现来运行.
需要一个Coordnator对象来管理这些线程.
1 | coord = tf.train.Coordinator() |
训练时,
1 | for step in range(10001): |
上面这种读取不是很好,可能会遇到一些错误,导致线程无法正常关闭,还在等待读取队列,必须强行kill掉才可以,可以采用官方的代码:
1 | try: |